This AI Lab project demonstrates an Enterprise Sales AI Copilot built for high-velocity revenue teams. Combining a robust, asynchronous FastAPI backend with LlamaIndex's localized indexing and OpenAI's state-of-the-art language models, this system transforms massive, unorganized PDF files—such as RFPs, security questionnaires, technical product specs, and legacy contracts—into an interactive, conversational brain in seconds.
For modern sales operations, speed is the ultimate competitive advantage. The bottleneck is rarely the sales call itself; it is the hours spent hunting through deep technical documentation, legal agreements, and product guides to answer critical prospect questions. This project showcases how to solve that bottleneck securely, keeping sensitive corporate data strictly contained within a local storage architecture.
This implementation was developed by Suhas Bhairav as part of a series focused on building production-ready, highly secure enterprise AI solutions with lightweight footprints.
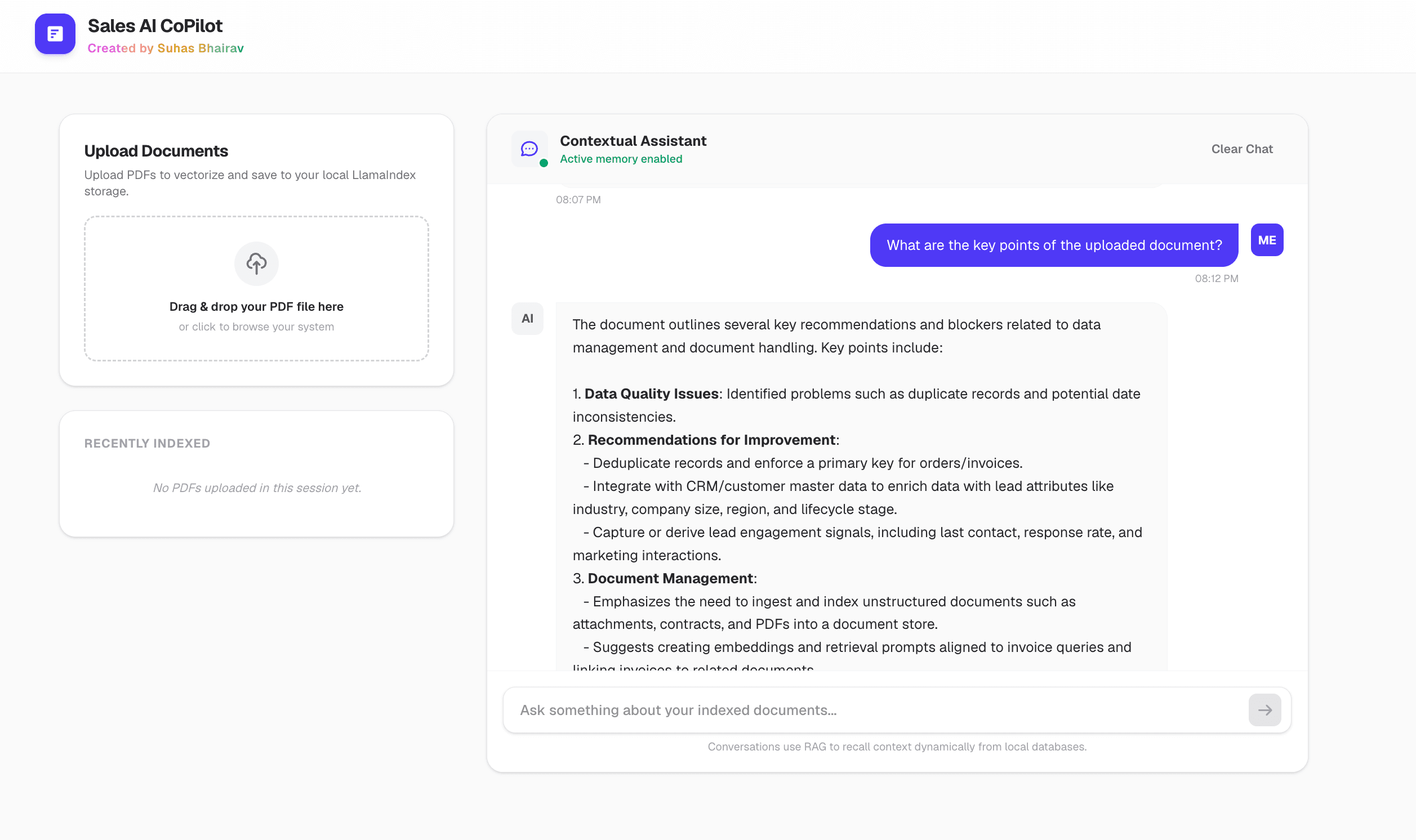
The Architecture: Why Local Vector Stores Matter to CTOs & CXOs
When deploying generative AI in enterprise sales, data governance is paramount. Uploading proprietary pricing strategies, pending client contracts, or pre-release product specifications to third-party cloud-hosted vector databases introduces compliance risks, high data transfer costs, and vendor lock-in.
This prototype demonstrates a localized vector persist-to-disk pattern. Utilizing LlamaIndex, incoming documents are parsed, chunked, and embedded on the fly, with their index tables written directly to a secure local folder within the application container itself. This architecture offers major benefits:
- Zero External DB Dependencies: No need to license expensive, cloud-only vector database subscriptions during early and mid-stage pilot programs.
- Airtight Compliance: Raw sales collateral remains within your network control, reducing the risk of third-party data breaches.
- Sub-Second Retrieval Latency: Because vector index lookups occur directly in local memory/disk space, the context generation speed outperforms remote database roundtrips.
Core Technical Capabilities
- FastAPI High-Concurrency Pipeline: Asynchronous file receiving and processing prevents API blocks when handling dense, hundreds-of-pages sales briefs.
- Dynamic Ingestion and Hot-Reload: Newly uploaded files are parsed on-the-fly and seamlessly merged into the active vector index without requiring server restarts.
- Intelligent Chunks & Embeddings: Generates semantic nodes using OpenAI's high-efficiency
text-embedding-3-smallmodel to capture contextual relationships. - Stateful Chat Engine with Memory: Utilizes LlamaIndex's
as_chat_engineincondense_questionmode to allow Sales Reps to ask follow-up questions organically without losing context. - Next.js Custom UI: Built with a light, premium aesthetic designed specifically for business users, featuring drag-and-drop feedback, file validation, and real-time generation indicators.
How It Accelerates the Enterprise Sales Cycle
Consider a standard enterprise B2B sales sequence. An Account Executive receives an 80-page Request for Proposal (RFP) containing complex security, compliance, and architectural questions. Under standard operating procedures, this RFP is routed across product, legal, and security teams—a manual process taking between 5 to 10 business days.
With this copilot, the pre-sales engineer drops the RFP and previous year's security questionnaires into the portal. Within seconds, they can query the engine: 'Draft an answer for Section 4.2 detailing our SOC2 Type II compliance and data isolation strategy.' The model instantly generates a customized response based entirely on the company's verified documents, shrinking draft turnaround from days to minutes.
Clean UI, Business-First Interactions
The companion Next.js frontend avoids cluttered terminal styling, embracing an intuitive interface tailored for executives. It features a polished branded navigation bar, a visual log of recently indexed files, and intuitive quick-action prompt suggestions to kickstart conversations instantly. For related GTM automation patterns, see real-time AI coaching for sales reps and AI-assisted sales proposal drafting.
Enterprise-Grade Extension Patterns
While designed as a localized standalone prototype, this pattern is architected to scale smoothly into enterprise production systems:
- CRM Integration: Link chat outcomes and document references directly with platforms like Salesforce, HubSpot, or Microsoft Dynamics.
- Hybrid RAG: Upgrade the local storage directory with a secure, clustered instance (such as Milvus, pgvector, or Qdrant) as document volume scales past tens of thousands.
- Role-Based Access Controls (RBAC): Connect FastAPI endpoints with OAuth2 / Active Directory, ensuring sales reps only query documents they have permission to see.
Strategic Value for Executive Teams
For CTOs and CXOs, this project demonstrates that building powerful, secure, and intuitive domain-specific AI tools does not require massive engineering budgets, expensive infrastructure contracts, or compromised data security. By combining lightweight, highly focused frameworks, companies can deploy custom intelligence tools that deliver massive, quantifiable ROI to their go-to-market teams from day one.
Conclusion
The Enterprise Sales AI Copilot proves how modern Python AI libraries can merge with clean web interfaces to solve tangible, high-impact business problems. It serves as a blueprint for organizations aiming to build robust, secure, and compliant RAG tools that keep humans in the driver's seat while drastically accelerating daily sales workflows. For adjacent executive-facing AI patterns, explore AI for shortening the B2B sales cycle and proposal-history agents for B2B service firms.
About the Builder
Suhas Bhairav builds production-grade AI applications, multi-agent systems, RAG architectures, and enterprise AI prototypes. For more implementation context, read AI agents for competitive battle cards and AI use cases for CRM notes and sales call summaries.